


世界の経済、信用、金利サイクルは非同期化(desynchronised)しつつある。これは、ある市場ではスプレッドが拡大し、レバレッジが上昇していても、他の市場では逆の状態であったりすることを意味する。日興アセットマネジメントのグローバルクレジットチームは、ファンダメンタル重視の投資アプローチを用いて、そうした状況下でも恩恵を得るべく世界のクレジット市場を分析し、トップダウンの投資テーマを確立している。クレジット市場の分析において、個々の企業の調査に際してはバランスシートのデータ分析、経営陣との対話、将来の企業の信用度を評価するためのキャッシュフロー予測など、ファンダメンタル重視のボトムアップ分析に依拠する。とは言え、アルファの源泉としてファンダメンタル分析を重んじる一方、我々は投資プロセスにおけるクレジットの選別(スクリーニング)の一助として定量モデルも使用している。グローバル全体で1,400社以上に及ぶ発行体から成るクレジットのユニバースに対し、個々の企業を全て、かつ細密にカバーすることは、リサーチチームにとって困難な課題だったが、このジレンマを克服するため、日興アセットマネジメントのグローバルクレジットチームは、企業の中期的なデフォルトリスク(株式市場、ファンダメンタルな会計データ、過去のデフォルトイベントなどに基づく)を予測するダイナミックな信用リスクモデルを開発した。これにより、運用チームは上述したユニバースのほとんどをカバーすることができるようになった。当モデルは、構築後もアナリストが絶えず改良を加えていることや、有望なバックテスト結果(図2参照)が見られることからポートフォリオマネージャーの間でも幅広く受け入れられている。
信用リスクモデルは、主に2つの目的のために開発された。
1)ハイイールドのスペースに関するリサーチにより多くのリソースを割くことができる
このモデルは、中期的なデフォルトリスクによって示唆される発行体の信用格付を推定するというものだが、信用力のスペクトルにおいては投資適格級(BBB- / Baa3以上)とクロスオーバー領域(ハイイールドと投資適格の境をクロスする領域)での活用をより重視している。この領域は、マーケットが新しい情報を価格(ひいてはデフォルト確率)に迅速に織り込むことができ、また会計情報も標準化され、アナリストによって広範にカバーされていること等から、最も情報効率が良いとされている。したがってデフォルト率のモデル化や予測に比較的適し、Type I エラーとType II エラー※1のバランスも望ましくなる領域と考えられる。こうして相当数の投資適格級・クロスオーバー領域の発行体を定量評価できる結果、チームはリサーチの重要性が一層大きいハイイールドのスペースにより多くの時間を割くことができる。
2)二次的な信用格付提供者として機能する
このモデルは、当社のインハウスにおけるファンダメンタルのクレジット評価に対して、追加的、かつ独立した二次的な評価として機能する。こうした評価に相違があった場合は、最終的な評価に達するまで、さらに検証を行うこともしばしばある。少し学術的な演習として、例えば企業Aを財務内容が悪化したエネルギーセクターの発行体とする。世界的に見て2016年のデフォルトの大部分が同セクターであったことからこの例を取り上げた。OPECが2016年後半に原油の減産合意に至る前は、世界的に供給過剰が進行、それに伴い原油価格がここ数年で最大の下落を記録する中、同セクター企業は非常に行き詰っていた。格付け機関はプロアクティブ(先行的)というより、リアクティブ(後続的)な傾向にあるが、当モデルであれば格付け機関が最終的に格下げを実施するよりもずっと前に、クレジットメトリックスや株価のバリュエーションの悪化と相まって、企業Aの推定信用格付けをCCC/D方向へ格下げ圧力をかけていただろう。早期の警告シグナルとしての当モデルの利点は明らかだが、誤ったシグナル(Type II エラー)を最小限に抑えるためアナリストのデューディリジェンスは必ず実施される。このモデルは2016年に運用プロセスに統合されて以来、発行体の信用リスクの悪化を早期に警告するシグナルとして、その能力を発揮している。モデルの詳細は下記の通りだ。
計量経済モデル
我々は、当モデルにおけるデフォルトの定義を「債務・借入に対する利子・元本を企業が返済不能となること、もしくは破産法の申請、または債務交換(ディストレスト・エクスチェンジ)が行われること」としている。
企業のデフォルト率を推測する我々のアプローチは、客観性、正確性、安定性、適時性の適切なバランスを取ることだ。これは、Altman(1968)のZ-Scoreに関する先駆的研究と、Merton(1974)モデルに組み込まれた経済理論(Altman他のZ-Metricsに似た、構造モデルと統計モデルの併用)を組み合わせることで可能となる(2010)。これらのモデルにはそれぞれに長所と短所があるが、デフォルト予測の最善のアプローチは株式市場と会計データを組み合わせることだと考える。どちらかだけでは、企業に関するすべての情報が完全に反映されているとは言えないからだ。デフォルトのリスクは、Mertonモデルのように先験的に特定されるのではなく、データそのものによって示される実証的な事象なのだ。例えば、Falkenstein他(2000)は、Merton型モデルが示唆するデフォルト率は、歴史的に観測されるデフォルト率と一致しないことを指摘している。とは言え、Mertonの経済理論は、株式の価値やボラティリティがデフォルトリスクとどう結びついているかについて非常に貴重な洞察を提供している。
先に述べたように、当社のモデルの基本要素はファンダメンタルのファクターと株式市場から得られる変数だ。ファンダメンタルのファクターとは、企業の信用度を図るとともにデフォルトを予測する上で統計的に重要な、財務指標等を指す。こうした説明変数としては、収益性、収益のボラティリティ、企業の時価総額、インタレストカバレッジ比率およびレバレッジ比率などだ。セクター間の一貫性を確保するため、一定の会計処理上の調整も行われる。我々のモデリング手法では、ファンダメンタルのファクターはAltman & Rijken(2004)の用いたエージェンシー格付け予測モデルを踏襲し、複数のファンダメンタルファクターのウェイトを客観的に決定する。そうすることで、説明変数の欠落や、変数間に高い相関が発生する問題を解消することができ、重回帰分析において一般的に問題となりうる二つの事象の発生を最小限に抑えることができる。
図1は、1995年から2015年の期間にわたる企業の格付け分布を示しており、オレンジがS&P の格付け、青紫が当社のファンダメンタルモデルに基づく格付けだ(赤紫が2つの格付けの重なりを示す)。これを見ると、当社のモデルが示唆する格付け分布は、概ねS&P の格付け分布と合致していることがわかる。ただ、当社のモデルの方がS&P よりも高い尖度を有し、BB格付近(図1では3)により多くの企業が属すると示している。この形状の違いは、S&P は格付け評価に「スルー・ザ・サイクル」(市場が発する短期的なリスク・シグナルに基づく「ポイント・イン・タイム」に対し、長期のトレンドを重視した信用力をはかる)の手法を用いていることに一部起因すると見られる。S&P は信用リスクの正確性と安定性(2大使命)のバランスをとるため、デフォルトリスクを決定づけるファクターとして扱う尺度を徐々に変化させてきたため、当社モデルとのギャップが生じたと考えられる。
図1: ファンダメンタルとS&P格付けの分布

出所:日興アセットマネジメント
このように、ファンダメンタルに基づくモデルと格付け機関(S&P 、以下の脚注を参照)の格付けには類似性が見られた一方、株式モデルは、近い将来デフォルトに陥るリスクに直面する企業に対して警告シグナルを発することを目的として、Shumway (2001) やChava &Jarrow(2004)といった先行研究を基に設計されている。
株式モデルに基づく結果は非線形の分析手法(デフォルトリスクと株式市場由来の3つのファクターとの間の非線形性をモデル化)によって統計学的に得られる。株式市場由来のファクターのうち2つは、Merton modelに根ざした経済理論を体現している。Mertonによると、企業の株式価値とボラティリティ(どちらも観察可能)の2つがデフォルトリスクと密接に関係しており、企業の資産価値が債務額を下回ることで、企業が株主によって倒産へ追い込まれる場合があるとしている。最後に株式市場由来のファクターの3つ目は、リスク調整後の超過リターンの指標だ。
次に、ファンダメンタルと株式モデルの結果について、過去1年から5年の期間でデフォルトした企業を特定できるデフォルト指標を使いながらCreditSightsの手法でモデル化する。 こうした推計を通じて、将来のデフォルト率を算出し、BloombergのDRSKやCitigroupの銀行デフォルトモデルとも類似した、デフォルト率のタームストラクチャー(期間構造)を構築することができる。
ここで、DPtをt-1年までの存続を条件とする、現在からt年までの企業のデフォルト率を予測するモデルとする。 iはモデルを示すものとし、?年=1,…,5 について得られるDPtを以下の式のように示すことができる。
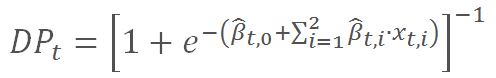
次に、各企業jについて、t-1年までの存続を条件とするt年のデフォルト率は次の式によって示される。
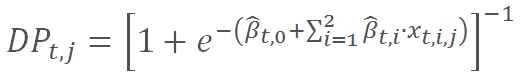
次に、累積5年のデフォルト率(CDP5,j)を、よりなじみ深い信用格付けの値に換算してみる。モデルによって導かれる格付けは、定期的に設定する閾値に基づいて推定される。閾値は格付けの各区分内の中央値?CDP5と格付け自体の関係を構築することで導くことができる。(この手法の方がタームストラクチャーに基づいて将来のデフォルト率が変動することによる影響をより小さくできるため)
CDP5,jは5年間の存続確率を累積することでDPt,jから以下のように計算される。
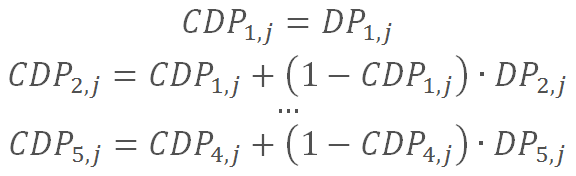
最後に、発行体の健全性に対する評価として、表1のようなマッピングを通じて企業に信用格付けが割り当てられる。このすべての値(1981年 – 2015年)がS&P が測定する同一の期間における世界の企業の平均累積デフォルト率と近似している。株式市場の過度のボラティリティも考慮し、格付け変更にあたっては、ある一定の条件を満たす必要があるとしているため、モデルが推計する格付けの頑健性※2も確保されている。例えば、CDP5は少なくとも1カ月間にわたって同じ方向へ動いていなければならない(すなわち、格下げにはCDP5が上昇方向へ、格上げには低下傾向へ動く必要がある)、といった条件だ。
表1: ファンダメンタルとS&P格付けの分布
| Rating | 5y CDP (Mid; %) |
|---|---|
| ≥AA- | |
| A+ | 1.17903 |
| A | 1.46998 |
| A- | 1.54342 |
| BBB+ | 2.10374 |
| BBB | 2.63029 |
| BBB- | 3.76100 |
| BB+ | 5.31654 |
| BB | 6.88803 |
| BB- | 9.26820 |
| B+ | 14.58487 |
| B | 19.33281 |
| B- | 25.37656 |
| CCC | 30.533352 |
| D |
出所:日興アセットマネジメント
予測能力テスト
図2は我々のモデルの受信者動作特性(ROC)曲線※3を示している。 デフォルト率モデルの予測能力は健全な企業と不健全な企業とを区別する能力で決まる。そうした尺度のうちで最も広く用いられるのが、ROC 曲線であり、主要指標であるROC 曲線下側面積(AUC=Area under the curve)だ。 ROC 曲線はカットオフ値を変動させながら描く。つまり、それぞれのカットオフ値について、X軸に「偽陽性率」(誤ってデフォルトとして分類される非デフォルトの%)をとり、その関数としてY軸に「真陽性率」(モデルがデフォルトとして正しく分類するデフォルトの%)をとって示したものがROC 曲線になる。45度の直線は、予測機能がでたらめであるROC 曲線を示し、ROC 曲線下側面積(AUC)が 0.5となる。これに対して AUCが 1 の場合には完全なモデルであることを意味する。我々のモデルの AUC は約0.73で、同じ期間について入手可能なその他のモデルと比較しても遜色ない水準となっている。
図2: ROC 曲線 (1995-2015年)
")
出所:日興アセットマネジメント
現状では、日興アセットマネジメントの信用リスクモデルは、株式が上場しており、非金融系、かつ格付機関によって格付けがなされている企業への応用に限定されている。株式市場から抽出される要素なしに(純粋にファンダメンタルの変数だけに基づいて)民間企業をモデルに当てはめることは可能ではあるものの、それではデフォルトに陥りそうな企業から発せられる早期警戒シグナルを受け取れないリスクがある。一方で、この課題は上場企業の各セクターのバリュエーション・マルチプルで代用することで解決される可能性もあり、我々は今後モデル向上のためにこうしたアプローチを追求するかもしれない。金融分野では、現在、金融機関(主に銀行)にも適用できるようなデータベースを構築するとともに、同セクターではどのような条件でデフォルトと見なすのか定義するプロセスを進めている。これは、ヨーロッパのように政府の救済措置により、企業が破たんに追い込まれない地域で重要になってくるだろう。こうしたモデルの改善が、チームのグローバルクレジットの投資ユニバースをさらに広げる助けとなると考えている。
結論
本論文では、日興アセットマネジメントにとってまさに第一号である企業デフォルト率モデルをご紹介した。モデルには、一定の産業固有の要素に加え、株価のパフォーマンスや会計指標などの企業固有の情報が組み込まれている。モデルを通じてデフォルト率の将来予想値を算出でき、これが差し迫ったデフォルトやクレジットサイクルにおける格付け変更のシグナルとして機能する。当チームは、アルファを生み出すべくファンダメンタルリサーチに大きく依拠しているが、定量モデルは我々の運用プロセスにおける極めて重要な補完手段として、チームの時間とリソースをより重要性の高い分野へ効率的に投下することに繋がると考えている。
脚注
可能な場合は常に、我々はS&P の実際の格付けを用いる。S&P の格付けが利用できず、ムーディーズの格付けが利用できた時はムーディーズを利用した。
※1統計的仮説検定の理論で用いる概念の1つ。観測資料にもとづいて統計的仮説を棄却するかどうかを判断する手順を定式化したものが統計的仮説検定。仮説として検定したい仮説(検定仮説という)とそれと対立する仮説(対立仮説という)とを考える。判断が常に正しいという保証はなく、誤った判断を下す可能性もあるが仮説検定の理論では誤りを2種類に区別する。検定仮説を棄却する(対立仮説を採択する)ことが誤った判断になっている場合をType I エラー(第一種の誤り)といい、検定仮説の採択(対立仮説の棄却)が誤った判断になっている場合をType II エラー(第二種の誤り)という。
※2ある統計手法が仮定している条件を満たしていないときにも、ほぼ妥当な結果を与えるとき、頑健(robust)であるという。
※3一般的に、スクリーニング検査等の精度の評価を測る際に使用される概念。
参考文献
- アルトマン、 E.I. (1968). 財務比率、企業破産の判別分析と予測、『ジャーナルオブファイナンス』、35. 1001-1016.ページ
- アルトマン E.I.およびライケン、 H.A. (2004).格付け機関はどのように格付けの安定性を実現するか、『ジャーナルオブバンキングアンドファイナンス』、28、 2679-2714ページ.
- アルトマン、 E.I.、ライケン、 H.A、ワット、 M、バラン、 D.、フォレロ、J.およびミーナ、 J. (2010)、 企業信用格付けとデフォルトリスク確率推計のためのZメトリクスTM 法、リスクメトリクスグループ
- ブルームバーグ (2017)、 DRSK公開会社『ブルームバーグ白書』、ブルームバーグLP.
- チャバ、S.およびジャロー、 R. (2004)、産業効果による破産予測、『レビューオブファイナンス』、 8(4)、 537-569ぺージ.
- ファルケンシュタイン、E.G.、 カーティ、 L.V.およびボラル、 A. (2000)、民間企業のリスク計算TM:ムーディーズのデフォルトモデル、『ムーディーズの投資家サービス特別コメント』
- マートン、 R.C. (1974).、企業負債の評価について:金利のリスク構造、『ジャーナルオブファイナンス』、29、 449-470ページ.
- シャムウエイ、 T. (2001)、破産のより正確な予測:単純なハザードモデル、『ジャ-ナルオブビジネス』、 74(1)、 101-124ページ.
- サリバン、 J. (2010)、.債券スコア:信用ポートフォリオ全体のデフォルトと格付け遷移リスクの管理、 IACPM. [オンライン] ニューヨーク: IACPM、 1-19ページ、 http://web.iacpm.org/dotAsset/16886.pdfで閲覧可能 [2016年12月30日にアクセスした].
- トン、 X. (2015)、銀行のデフォルト確率のモデル化、『アプライドエコノミクスアンドファイナンス』、 2(2) 、29-51ぺージ.
- バシチェック、O. (1984)、信用評価、 『KMV 白書』、KMV LLC.



